
Abstract
High-throughput materials research is strongly required to accelerate the development of safe and high energy-density lithium-ion battery (LIB) applicable to electric vehicle and energy storage system. The artificial intelligence, including machine learning with neural networks such as Boltzmann neural networks and convolutional neural networks (CNN), is a powerful tool to explore next-generation electrode materials and functional additives. In this paper, we develop a prediction model that classifies the major composition (e.g., 333, 523, 622, and 811) and different states (e.g., pristine, pre-cycled, and 100 times cycled) of various Li(Ni, Co, Mn)O2 (NCM) cathodes via CNN trained on scanning electron microscopy (SEM) images. Based on those results, our trained CNN model shows a high accuracy of 99.6% where the number of test set is 3840. In addition, the model can be applied to the case of untrained SEM data of NCM cathodes with functional electrolyte additives.
Similar content being viewed by others

Introduction
Lithium-ion battery (LIB) system consists of anode, cathode, electrolyte, separator to name few. The interaction between each component is very complicated, which hinders the full understanding of all the interactions needed for developing high performance LIBs1. Furthermore, there are a lot of factors affecting the overall capacity and cyclability even in the single component2.
For instance, the nano- to micron scale structure, and composition affect the specific capacity and rate capability of the whole cell3,4. As such, various analysis and visualization tools are utilized to analyze the complicated interactions between each component such as primary/secondary particles of cathode materials, functional binders, and solid-electrolyte interphase (SEI) layer5,6,7. To characterize SEI layer, various inspection tools such as scanning electron microscopy (SEM), TEM, AFM, X-ray photoemission spectroscopy, Fourier transform infrared spectroscopy, and electrochemical impedance spectroscopy (EIS) are used to measure its physical and chemical properties8,9,10,11.
Among those methods, SEM is one of the popular, easy, and intuitive techniques to characterize the morphology of active materials and particle distribution to capture different states of the electrodes. However, the analysis of acquired images is strongly dependent on the domain experts’ knowledge and experience12,13. In these regards, interpretable analysis tools using artificial intelligence and machine learning approaches are being developed because they are free from human subjectivity, have data-driven results, and are able to analyze big data at the same time14,15,16,17,18,19,20.
As machine learning can accelerate the process of human-dependent labor-intensive analysis21,22,23,24,25,26, we propose to apply machine learning with class annotation only, to extract composition and state of the specific NCM cathode based on the SEM images. We acquired various SEM images of Li(Ni, Co, Mn)O2 (NCM) electrode in different states and compositions and used them as the input of the machine learning model. The reason we chose different nickel content of NCM electrode with or without functional additives is because it is the mostly used cathode materials in electrical vehicles and energy storage system.
Here, we develop a prediction model of various NCM cathode states such as compositions (Ni = 0.3, 0.5, 0.6, and 0.8 while all summation of Ni, Co, and Mn is 1) and conditions (pristine, formation (less aged) and 100 cycles with 1 C-rate (aged)), and apply the model to various NCM electrodes with functional additives without any further learning to check the extendibility of our model. For qualitative analysis, we compare the survey accuracy of 14 domain experts with the accuracy of our model.
Results
When working with collaborators from battery industry, we found that the domain experts could frequently distinguish each component by merely looking at the morphology of particles in SEM images. This could be due to the fact that SEM brightness is correlated with the specific elements such as electron density, and the morphology of a particle in SEM images is mostly determined by the composition of such elements. Furthermore, they could also point out whether the image contains a pristine or a cycled particle based on the fact that pulverization leads to smaller-sized particles as a function of charge and discharge cycles. For those reasons, SEM offers intuitive information about the chemical composition and the cycled state in an easily accessible way within a few minutes.
As such, we wondered if we can systematically characterize the composition and state of the active materials by using computer vision-based machine learning algorithm. In order to correlate visual representation information with the composition and cycle states of LIB cathode electrodes, we utilized a computationally efficient CNN model named EfficientNet, which was designed for classification applications using dimension scaling technique in 201727.
We conducted SEM imaging of various NCM cathode materials, which include four different Ni contents (Ni = 0.3, 0.5, 0.6, 0.8 at NCM cathode) and three cycled states (pristine, formation, and cycled for 100 times). The SEM images were acquired under 500 times magnification to identify each NCM electrode state. The total number of images is 1637 before augmentation process. Before training, we first augmented all the images, resulting in 2400, 600, and 600 images for the training, validation, and test sets, respectively.
To have sufficient number of training and validation images for our CNN model, we systematically augmented the data by cropping the images. The original SEM images were subdivided into several sizes and evaluated to maximize the prediction accuracy efficiently because of limited computational resources.
Specifically, the observed SEM images were cropped into designated sizes of sub-images (training and validation images) with randomized x and y coordinates to comprise the entire NCM particles (2nd particle mainly). The size and number of sub-images are one of the hyper-parameters needed to be optimized, of which details can be found in “Optimization of CNNs”. The best dataset has 4800 images, which consists of 80% training and 20% validation sets randomly selected from generated sub-image set.
After composing the dataset, we have trained CNNs under Ryzen 7 3800XT 8-core processor, 64 GB RAM, and NVIDIA GeForce RTX 3080 with 10 GB VRAM system. Elapsed training time takes ~2 h and inference time for 360 images is less than 5 min. Typical hyper-parameters such as learning rates, size of training batch, and color normalization were optimized via the Asynchronous Successive Halving Algorithm (ASHA) provided by Ray Tune package28.
With the help of ASHA, a bandit algorithm searches29 the next options to train the model for finding the highest accuracy within 20 epochs. Afterwards, the trained model estimates the composition in terms of Ni, Co, and Mn contents and their cycle state from given SEM images.
For comparison, we conducted a domain expert survey using a Google Document format (https://forms.gle/9dBd3GG8FCnNHQPK8). As SEM images of cathode materials were used for many studies, domain expert has morphological and electrochemical understandings to determine the composition and state. Determining accuracies of CNN and human researchers has been described in the following section. Overall workflow is summarized in Fig. 1.

The workflow starts with data acquisition, proceeds through data augmentation, model training, and ends with prediction. The prediction accuracy surpasses that of domain experts.
Performance of CNN
The best network classified the NCM images correctly with an accuracy of 99.6% among 2430 test images from 12 categories, which include the composition of NCM samples and cycling states.
Figure 2 illustrates representative SEM images with the size of 300 × 300 pixels and guided gradient class activation map (grad-CAM) overlays30 on SEM images. The images in each row have the same NCM composition and that of each column shares the same cycling state. NCM cathode consists of primary particles (diameter of hundreds of nanometers) and secondary agglomerates (diameter of tens of micrometers) after processing and cycling steps of which morphology is composition dependent.

a Example images of true cases and their grad-CAM overlays from the best trained network. b Probability of each class for false case and grad-CAM overlays of top-most highest classes. c Results of predicting composition and cycling state of SEM images from domain experts.
For a few cycles of charge and discharge, chemical reactions between the cathode and electrolyte generally generate SEI that facilitates smooth ion movement in and out of cathode during lithiation and delithiation processes.
The existence and growth of the SEI layer affects the lifetime of battery, which necessitates the understanding of the SEI layer. However, the thickness of the cathode-electrolyte interphase (CEI) that is a SEI layer at cathode side is typically less than 100 nm, which can be challenging to capture and analyze by using SEM images quantitatively. Especially, for high nickel NCM, the CEI property is more critical to cathode performance31,32. Another factor influencing the performance of LIBs is the volumetric expansion and contraction of electrode materials during lithium-ion diffusion, which occurs inevitably with the ionic current flow back and forth. This leads to structural changes and electrochemical instability which cause degradation in overall capacity of battery cells32.
Nevertheless, the SEM can capture the microstructural changes near cathode particles, which is difficult to spot and describe in detail for the human researchers, and these descriptors can be correlated to their states with the help of CNNs.
In order to understand the decision-making process of CNNs, we generated grad-CAM images, as shown in Fig. 2a. The grad-CAM technique pulled the fitted gradients out to understand the importance of each layer, visualizing feature maps to the designated target classes30. Thus, the red areas of grad-CAM images in the form of heatmap were positively connected to the predictions from the trained model while the blue areas negatively. In addition, we evaluated the prediction in the test using confusion matrix and the classification report that contains precision, recall, and F1-score, as shown in the Supplementary Fig. 1 and Supplementary Table 1 below, respectively. As we can see in the confusion matrix above, the majority of the image classes were correctly classified. However, several of NCM333 formation and NCM811 cycled images were incorrectly classified, leading to a low recall below 0.90 (0.72), and low precision below 0.90 (0.81), respectively, as shown in the Supplementary Table 1 above. Other classes have precision and recall above 0.90, which is good. Overall, the total accuracy determined by the F-1 score is high (96% or 0.96).
Although the same magnification has been used for capturing all the NCM cathode materials, there are brightness and image quality variations due to the complex interaction between the cathode materials and electron beam. The intensity of SEM images typically varies depending on the conductivity of samples near the surface. The grayscale levels can be adjusted by controlling the accelerating voltage of electron beam and the aperture ratio of lens.
Nevertheless, acquiring similar level of brightness and contrast across different images is very tedious and difficult. As such, normalizing the brightness and contrast levels inside the augmentation process might be needed. However, our attempts to normalize the images did not result in better performance.
Based on Supplementary Fig. 2, each histogram in different composition and state of NCM cathode materials shows different slopes and distributions. Furthermore, Supplementary Fig. 2 and Supplementary Fig. 3 show that training and validation images show similarity of slope and distribution with insignificant average and standard deviation, which is also captured in Supplementary Table 2. These results mean that normalization of each image may reduce information dimension, which is detrimental for at least estimating the composition and states of NCM cathode materials.
Indeed, using the original images resulted in much better performance, which is counter-intuitive. Specifically, when we used normalization process to test the best model, the model classified the state of images with very low accuracy of 20% with the same test dataset. Thus, we speculate that color distributions of SEM images are carrying some of state information, which was removed during normalization processes. The distributions of training and test image datasets as shown in Supplementary Figs. 2, 3 and Supplementary Table 2 have characteristic shapes, but it is hard to distinguish the states of cathode materials based on this pixel counts. Furthermore, because of large contrast levels, normalization throughout the dataset causes grayscale clipping effect that is information loss from exceeding threshold value (0–255) likewise washed out in photography.
In order to understand how our CNN predicts the composition and state accurately without normalization process, we examined the grad-CAM overlay images, in which most of high reaction points were located in the boundary of particles and gap between particles. If most of the high reaction points were located in the center of the particles or disconnected points on the particles, we would speculate the importance of the size and morphology of the particles to predict each composition and state. Therefore, the reason our model shows high accuracy was because it captures the shape and length of boundaries between particles in addition to the contrast level of the image to predict the composition and state.
Although some cases including NCM523 formation and NCM523 cycled contain some impurities or by-products than other cases, the model bypasses such anomalies and captures the interfaces between secondary particles. In addition, in most cases showing well-defined secondary particle shapes, the grad-CAM overlay images indicate strong intensity along particle boundaries such as NCM622 pristine and NCM622 formation cases. In the case of Ni-rich composition (NCM811), the size of secondary particles is smaller than other compositions33,34, and red area of grad-CAM overlay covers pits generated from small secondary particles.
We also analyzed misclassified cases, of which number was 10 among 2430 test images. one of misclassified case predicted NCM523 pristine state from NCM622 pristine image. To see the decision process in more detail, we plotted the probabilities of all class as shown in Fig. 2b. We found that the model picked NCM523 with probability of 66.2%, which was larger than NCM622 with probability of 33.8%. It should be noted that other composition was not even considered, showing strong capability of distinguishing samples with large difference in composition.
When we compare the SEM images in true cases of NCM523 and NCM622 in Fig. 2a, it is difficult to define characteristic features to determine what belongs to NCM622 class or NCM523. Likewise, grad-CAM images of two most prominent classes show similar spatial distribution of red and blue areas, which might have contributed to the error in the prediction.
Distinguishing the morphologies of cathode materials with naked eyes is difficult even for domain experts. We gathered the responses from 14 domain experts matching the visual representation to their different states (composition and cycling state) of 19 SEM images, which is plotted in Fig. 2c. The highest score from the survey was 13 out of 19 given images, which is 68.4%, and the average number of the correct match was 5.71 out of 19, which is 30.0%.
Qualitatively, domain expert assumed the size of particles in the presented image was related to the composition in terms of Ni content and the roughness of the boundary between particles implied cycling states. Some of the experts complained that the by-products from cycling steps were accumulated on the particles, which might degrade the quality of SEM images rendering poor judgment. Based on our survey, we claim that it is challenging to match the morphologies to compositions and cycling states without any provided information using an intuitive way.
Optimization of CNNs
By using ASHA and bandit algorithms, hyper-parameters were optimized through grid search on parameter space. The learning rate, image augmentation methods including random rotation and flipping, and batch size were tested for training accuracy under 20 epochs in each candidate. The image augmentation methods including flipping and rotation were removed after optimization process, and using pretrained weight can help fit the model on SEM images of electrode materials.
Although the ImageNet dataset, which is dataset used for pretraining process, does not share the same features as those of electrode materials, the CNNs trained on the ImageNet dataset settle down faster than CNNs with random weights, which is also the case in other fields35,36,37. The learning rate was selected to be 3.5 × 10−4 from 0.0001 to 0.1 on uniform log scale grid search and batch size to be 10 images. Along with provided handy tool for typical hyper-parameters including learning rate, batch size, and grayscale normalization, we trained CNNs with various image sizes and number of training images to have most accurate network model.
Figures 3a, b, e, f plot the resulting accuracies of training and validation sessions during optimization process. Initially, the EfficientNet model was designed for the size of 224 × 224 pixels, which is known for size of ImageNet datasets38. Therefore, the image augmentation process was conducted close to 224 × 224 pixels ranging from 100 × 100 pixels to 400 × 400 pixels.

a, b Training and validation accuracy varying the size of images. c test accuracy varying training image size and 224 × 224 pixel case is selected because the model is aiming for the ImageNet dataset, which has 224 × 224 sized images. d examples of cropped training images with scale bar length of 20 µm, and e, f training and validation accuracies as a function of epochs for different number of training images.
After cropping, the total number of pixels in the images was resized to 224 × 224 pixels as the input dimension is fixed at 224 × 224 pixels. However, the length and width of the images were invariant to keep the same size measured from the SEM images. So, each image carries different number of particles and structural contexts on training and validation sessions causing local optimum of 300 × 300 pixels as depicted in Fig. 3c.
In Fig. 3d, the selected SEM images with different cropped sizes are shown. The average electrode particle size of the full dataset is ~12 μm, so the number of particles in the image varies from few tens to few hundreds.
From the low prediction accuracy in small-sized images, we speculate that the prepared image dataset does not carry sufficient information to correctly classify the given test sets. On the other hand, if the size is too large, the model tends to lose the detailed features, which may be related to the composition and the cycled state. As such, the test accuracy shows a bell-shaped curve as a function of the image size as shown in Fig. 3c.
We also investigated the optimum number of training and validation images, which was varied by subdividing the original SEM images. This was to find the best network with smallest datasets and shortest elapsed time for fitting. If randomly cropped area is not covered sufficiently, it is difficult to transfer the context of NCM latent features for predicting their composition and cycling states.
As the number of images in each class increases, the epochs reaching optimal points in validation process increases as depicted in Fig. 3f. The CNNs were optimized for training image datasets mostly within 10 epochs because they contain pretrained weights in structured manner for classification applications.
Another factor in optimization process is the elapsed time for fitting the neural network model. Although the performance increases with increasing the number of images, the iteration time also increases for each epoch with the size of training datasets. The elapsed time for a single epoch using training dataset increases linearly from ~20 s to ~190 s when the number of images increases from 50 to 500 based on Fig. 3e. In case of validation dataset, the saturated accuracy increases from ~90% to ~98% as the number of images increases from 50 to 500 based on Fig. 3f. Furthermore, the minimum number of epochs to reach the saturated accuracy is 2 for 400 images, as shown in Fig. 3f. Thus, we conclude that increasing the number of images above 400 for a single set does not enhance the performance of the model significantly. As such, we used 400 images with 300 × 300 pixels for training network that predicts the composition and cycling states of NCM cathodes.
Finally, we investigated the impact of the SEM magnification level on the model. We tested our model, trained on the images with different magnification of 100×, 500×, and 5000× in Supplementary Fig. 4. As we can see from Supplementary Table 3, the magnifications level does not affect the accuracy significantly. Therefore, we found that the accuracy does not improve with increasing magnification to our surprise. Based on these results, we claim that higher magnification does not allow for training with smaller data sets.
In addition, accelerating voltage is clearly affecting the brightness and contrast of the SEM images as shown in Supplementary Fig. 5, so we used this parameter to see if it affects the accuracy of our model. To save time and cost, we used pristine samples with different nickel content, namely NCM333, NCM622, and NCM811. However, as we can see from Supplementary Table 4, the accelerating voltage does not significantly affect the accuracy of model. Therefore, we think that normalization throughout the dataset caused grayscale clipping effect, which led to information loss from exceeding threshold value (0–255) as in the case of washed-out in photography rather than losing information from the brightness and contrast of SEM images.
To strengthen the impact of our work, we trained the same machine learning algorithm with NCM images obtained using optical microscopy (OM) with magnifications of 5×, 10×, 20×, 50×, and 100×. Optical microscopes would be significantly cheaper to implement in manufacturing and the demonstration that an ML model can be used to elevate a simple instrument would be significant. To avoid large investments in time and cost, we just used the pristine NCM samples: pristine NCM333(16 images), pristine NCM622 (11 images), and pristine NCM811 (10 images). Before training, we first augmented all the images, resulting in 2400, 600, and 600 images for the training, validation, and test sets, respectively. After that, we performed training and validation, and the resulting trained model performances are shown in Supplementary Fig. 6. The loss function curves for training and validation are decreased, and their corresponding accuracies are increased after training for 40 epochs, indicating that the model is suitable for classifying the NCM images obtained using the OM, as shown in Supplementary Fig. 6a, b. The test’s confusion matrix shows that most images could be classified correctly. Only eight pristine NCM811 images and four pristine NCM333 images were misclassified into eight pristine NCM622 images and four pristine NCM811 images, respectively, as shown in Supplementary Fig. 6c. The classification report in the test set shows high precision and recall, and the total accuracy is 98% (0.98), as shown in Supplementary Table 5. Therefore, our machine learning algorithm adapting OM images was confirmed with high accuracy of electrodes estimation.
We investigated the preprocessing effect of histogram equalization techniques, CLAHE for preventing clipping effect in the SEM images. Supplementary Fig. 7 shows the comparison of the SEM image samples without the CLAHE equalization technique (left) and with the CLAHE equalization technique (right). Based on the results, the application of CLAHE to the SEM images has improved the visual quality by enhancing the contrast and bringing out details that were less visible in the original images. To verify loss and accuracy effects by CLAHE equalization, Supplementary Fig. 8 shows a loss function where the validation loss is much higher and more volatile than the training loss, indicating a degree of overfitting as the model learns the training data well but fails to generalize these learnings to unseen data. Supplementary Fig. 9 presents the accuracy over epochs, with training accuracy reaching near-perfect levels, while validation accuracy fluctuates significantly, reinforcing the suggestion of overfitting. Supplementary Fig. 10 is a confusion matrix of the test set, which shows high true positive rates for most classes. The overall high accuracy, however, is contradicted by the lower values in some classes. Some classes, such as 523_formation and 523, have a large number of misclassifications as shown in the confusion matrix. From this observation, we speculate that even though the CLAHE can improve the visual quality of the SEM images by enhancing the contrast, it actually degrades the normalized SEM images because when they were used as the input into the model, the performance of the loss function, accuracy, and confusion matrix are much worse than those without the CLAHE and normalization process.
Predicting state of cathode with functional additive using untrained CNN networks
It is well known that the functional additive enhances LIB performance by e.g., generating electrochemically and mechanically robust interface between electrode and electrolyte39. For example, some additives such as vinylene carbonate (VC) and 1,3-propane sultone (PS) significantly enhance the capacity retention, by generating stable interfaces in both cathode and anode40,41,42,43,44,45,46.
In order to check the extended applicability of our trained CNN to other types of NCM cathode, we applied our best-trained models to NCM333, NCM622, and NCM 811 electrode materials with additives which were not included in our training dataset. Figure 4a illustrates the compositional and state accuracies of each category. The accuracy of overall prediction in composition and cycling state was 34.17%, which limits the direct application of our model to NCM cathodes with additives. However, the overall compositional accuracy was 96.0% implying that SEM images of electrode materials with or without additives share common features and the trained CNN captures the characteristic descriptors to predict their compositions.

a Prediction accuracies on SEM images of electrode materials with additives under various conditions. b Examples and grad-CAM overlays of electrodes containing 2 wt% vinylene carbonate (VC) + 1 wt% 1,3-propane sultone (PS) additives.
Especially in the case of NCM 622 after formation, the trained CNN predicted the composition and cycling state with 91.0% accuracy. Based on this high accuracy, we assume that NCM622 samples with and without additives are sharing common visual representation while undergoing formation cycle.
The examples of SEM images and grad-CAM overlays from cathodes with or without additives are shown in Fig. 4b. As discussed in the previous section, it is almost impossible even for domain experts to specify the latent common features that are correlated with cycling states.
The existence of functional additives in electrode materials might either reduce the rate of degradation, which may be the cause of underestimating the number of cycles like judging cycled state to be formation or induce jittering in the boundary area that misleads the cycling state predictions from 100 cycles to formation cycle. Through grad-CAM overlays, the best CNN still pays attention to the boundary and gap between particles in additive cases as trained dataset. This means the model behaves like domain experts catching dominantly the interface topographies to predict properties.
Discussion
We correlated the surface morphologies of NCM cathode materials captured by SEM images with the compositions and electrochemical states using an EfficientNet-based CNN model. Our model showed 99.6% accuracy of both composition and cycled state classification, which is much higher than 30% accuracy of domain experts.
We speculate that the most important features for understanding the relationship between physical structure and compositions are coming from interfacial area of primary and secondary particles based on the analysis of the guided grad-CAM images.
The size of training images was determined by the number of particles in the SEM images and the structure of pre-defined model architecture. In order to confirm wider applicability of our model to other cathode materials, we classified untrained SEM images obtained from samples with functional additive (base electrolyte + 2 wt% VC + 1 wt% PS additives), resulting in 96.0% of accuracy for predicting the composition but 34.17% of accuracy for predicting the cycling state.
As such, we think that our current model has a limitation to recognize the state of an untrained electrode. If the NCM particle with the same composition is developed by a different company, we should include them in the training set to enhance the accuracy.
Methods
Preparation of samples
The NCM (NCM333 (LiNi1/3Co1/3Mn1/3O2), 523 (LiNi0.5Co0.2Mn0.3O2), 622 (LiNi0.6Co0.2Mn0.2O2), and 811 (LiNi0.8Co0.1Mn0.1O2), L&F Co. Ltd., Korea) were used as cathode active material and lithium metal foil (Honjo Metal Co., Japan) was used as an anode active material. The NCM cathode was fabricated by coating a slurry, mixture of NCM (94 wt%), carbon black (Super P, Timcal, 3 wt%) as a conducting agent, poly(vinylidene fluoride) (PVdF, Aldrich, 3 wt%) as a polymer binder in N-methyl-2-pyrrolidone (Aldrich) as a solvent, onto Al foil (10 μm thick) as a current collector, drying in a vacuum at 100 °C for 24 h, and pressing with a line pressure of 1000 kgf. The active mass loading of the cathode film was 18.3–20.5 mg cm−1. The coin-type cell (2032) for electrochemical performance tests was fabricated by sequentially superimposing the NCM cathode, the polyethylene separator, and Li foil anode, and injecting 400 μm of the liquid electrolyte sample. Each NCM electrochemical cell was prepared to observe variation of NCM performance (total 3 samples). The liquid electrolyte used was a commercial liquid electrolyte (Enchem Co., Ltd., Korea) of 1 M LiPF6/ethylene carbonate (EC): ethyl methyl carbonate (EMC) (3:7 v/v) battery grade. In addition, the functional additives were 2 wt% VC and 1 wt% PS.
Electrochemical performance and characteristics
Galvanostatic charge-discharge cycling testing of the NCM/Li coin cell was carried out using a cycler (Toscat 3000, Toyo Systems, Japan) in the voltage range of 3.0–4.3 V using a formation protocol and the consecutively specified charge-discharge program. The formation protocol was charge-discharge cycling at 0.1 C (14 mA g−1 at NCM333, 15 mA g−1 at NCM523, 17 mA g−1 at NCM622, and 20 mA g−1 at NCM811) for the first cycle on constant-current and 0.2C for the 3 formation cycles on constant-current/constant-voltage (0.02C) mode. The cycle tests were performed with 1 C for 100 cycles. Supplementary Fig. 11 shows the measured specific discharge capacity as a function of cycle numbers for different NCM composition. Each test was conducted for three times to calculate the standard deviation of the specific capacity.
The NCM/Li coin cell was disassembled after cycling and the surface part of the cathode sheet was extracted to investigate the morphology variation of electrode-electrolyte interphase and particle cracks. Before obtaining the SEM images, we washed the electrode with DMC (Dimethyl carbonate) after disassembling the cell. We dried it in the vacuum oven at room temperature for 12 h and took SEM images. All processes including washing and observing the electrode were conducted inside a dry room (dew point < −50 oC).
We acquired scanning electron microscopy (SEM, SEC SNE-4500M Plus) images of NCM cathodes at different states (pristine, formation and cycled) from 100 positions, which were used in training and test datasets. We controlled the contrast and brightness by aperture ratio of lens (manually) with constant accelerating voltage of 20 kV.
Image augmentation methods
It is difficult to acquire SEM images covering all of sample surface carrying the structural context of electrode materials. Firstly, we collected test images (10% of the full dataset) from each class before splitting the dataset. Then, we cropped the test images to check the performance of the trained network. Afterwards, 20% of the full dataset except the test dataset were selected for validation process.
Random coordinates of rectangle, which are not overlapping with the informatic area of SEM images, were generated to divide large SEM images. The number of generated random coordinates can be altered for the optimization process.
The designated number of images is the sum of training and validation images, so 80% of generated images from the predefined training set goes into the training dataset and the remaining 20% goes into validation dataset. In order to avoid clipping problems, that is black-out or white-out of features when we normalize the images having large grayscale range, we didn’t apply color normalization, which is typically processed in classification applications. Also, other image augmentation methods including random rotation and flipping were tested.
EfficientNet architecture
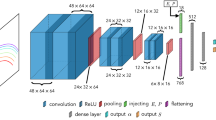
We utilized state-of-the-art image classification network structure called EfficientNet which has been developed in 201927. The main structure follows previously opened to public named MNasNet, which is illustrated in Fig. 5a. Details of each MBConv blocks were explained as Fig. 5b, c, which has tunable convolutional layers. One of the important considerations of machine learning application is the efficiency. During training and actual functioning environments, the designed architectures should respond fast and accurate. In order to accomplish this goal, the developers brought “compound scaling” method that is controlling the dimensions inside of architectures under constraint resources. Typical CNNs having large dimensions show high accuracy, but take a lot of computational resources. The depth, width, and resolution of the models were parameterized comparing the profits using following equations:
subject to α ∙ β2 ∙ γ2 ≈ 2, α ≥ 1, β ≥ 1, γ ≥ 1. Under this constraint, number of calculations is proportional to 2ϕ, and parameter ϕ controls the dimensions that is directly related to the number of weights. In this study, we used the model named “EfficientNet-b7” having 66 million parameters and requiring 37 billion FLOPs.

a Overall network architecture which is based on the MNasNet framework. b Details of MBConv1 block consists of 6 layers. c Details of MBConv6 block containing 9 layers.
Data availability
The authors declare that the data supporting the findings of this study are available within the article and its supplementary information files or from the corresponding authors on reasonable request.
Code availability
Code is available at https://github.com/MIIMSEKAIST/CNN_for_NCM-composition-and-state-prediction.
References
Armand, M. & Tarascon, J.-M. Building better batteries. Nature 451, 652–657 (2008).
Manthiram, A. A reflection on lithium-ion battery cathode chemistry. Nat. Commun. 11, 1550 (2020).
Poizot, P., Laruelle, S., Grugeon, S., Dupont, L. & Tarascon, J.-M. Nano-sized transition-metal oxides as negative-electrode materials for lithium-ion batteries. Nature 407, 496–499 (2000).
Croce, F., Appetecchi, G. B., Persi, L. & Scrosati, B. Nanocomposite polymer electrolytes for lithium batteries. Nature 394, 456–458 (1998).
Xu, Y. et al. Promoting mechanistic understanding of lithium deposition and solid‐electrolyte interphase (SEI) formation using advanced characterization and simulation methods: recent progress, limitations, and future perspectives. Adv. Energy Mater. 12, 2200398 (2022).
Xu, K. Electrolytes and interphases in Li-ion batteries and beyond. Chem. Rev. 114, 11503–11618 (2014).
Scharf, J. et al. Bridging nano- and microscale X-ray tomography for battery research by leveraging artificial intelligence. Nat. Nanotechnol. 17, 446–459 (2022).
Liu, X. et al. Bridging multiscale characterization technologies and digital modeling to evaluate lithium battery full lifecycle. Adv. Energy Mater. 12, 2200889 (2022).
Cheng, D., Lu, B., Raghavendran, G., Zhang, M. & Meng, Y. S. Leveraging cryogenic electron microscopy for advancing battery design. Matter 5, 26–42 (2022).
Lin, F. et al. Synchrotron X-ray analytical techniques for studying materials electrochemistry in rechargeable batteries. Chem. Rev. 117, 13123–13186 (2017).
Huang, B., Li, Z. & Li, J. An artificial intelligence atomic force microscope enabled by machine learning. Nanoscale 10, 21320–21326 (2018).
Wang, X., Li, Y. & Meng, Y. S. Cryogenic electron microscopy for characterizing and diagnosing batteries. Joule 2, 2225–2234 (2018).
Sulzer, V. et al. The challenge and opportunity of battery lifetime prediction from field data. Joule 5, 1934–1955 (2021).
Chen, C. et al. A critical review of machine learning of energy materials. Adv. Energy Mater. 10, 1903242 (2020).
Vidal, C., Malysz, P., Kollmeyer, P. & Emadi, A. Machine learning applied to electrified vehicle battery state of charge and state of health estimation: state-of-the-art. IEEE Access 8, 52796–52814 (2020).
Chun, H., Kim, J. & Han, S. Parameter identification of an electrochemical lithium-ion battery model with convolutional neural network. IFAC-PapersOnLine 52, 129–134 (2019).
Zheng, H., Lu, X. & He, K. In situ transmission electron microscopy and artificial intelligence enabled data analytics for energy materials. J. Energy Chem. 68, 454–493 (2022).
Wei, J. et al. Machine learning in materials science. InfoMat 1, 338–358 (2019).
Andersson, M. et al. Parametrization of physics-based battery models from input–output data: a review of methodology and current research. J. Power Sources 521, 230859 (2022).
You, G., Park, S. & Oh, D. Real-time state-of-health estimation for electric vehicle batteries: a data-driven approach. Appl Energy 176, 92–103 (2016).
Gu, G. H., Noh, J., Kim, I. & Jung, Y. Machine learning for renewable energy materials. J. Mater. Chem. A Mater. 7, 17096–17117 (2019).
Butler, K. T., Davies, D. W., Cartwright, H., Isayev, O. & Walsh, A. Machine learning for molecular and materials science. Nature 559, 547–555 (2018).
Schmidt, J., Marques, M. R. G., Botti, S. & Marques, M. A. L. Recent advances and applications of machine learning in solid-state materials science. NPJ Comput. Mater. 5, 83 (2019).
Benkedjouh, T., Medjaher, K., Zerhouni, N. & Rechak, S. Remaining useful life estimation based on nonlinear feature reduction and support vector regression. Eng. Appl. Artif. Intell. 26, 1751–1760 (2013).
Ramprasad, R., Batra, R., Pilania, G., Mannodi-Kanakkithodi, A. & Kim, C. Machine learning in materials informatics: recent applications and prospects. NPJ Comput. Mater. 3, 54 (2017).
Nuhic, A., Terzimehic, T., Soczka-Guth, T., Buchholz, M. & Dietmayer, K. Health diagnosis and remaining useful life prognostics of lithium-ion batteries using data-driven methods. J. Power Sources 239, 680–688 (2013).
Tan, M. & Le, Q. V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. Preprint at https://arxiv.org/abs/1905.11946 (2019).
Li, L. et al. A System for Massively Parallel Hyperparameter Tuning. Preprint at https://arxiv.org/abs/1810.05934 (2018).
Yu, T. & Zhu, H. Hyper-Parameter Optimization: A Review of Algorithms and Applications. Preprint at https://arxiv.org/abs/2003.05689 (2020).
Selvaraju, R. R. et al. Grad-CAM: visual explanations from deep networks via gradient-based localization. In Proc. 2017 IEEE International Conference on Computer Vision (ICCV) 618–626 (IEEE, Venice, Italy, 2017).
Oh, J. et al. Effects of vinylene carbonate and 13-propane sultone on high-rate cycle performance and surface properties of high-nickel layered oxide cathodes. Mater Res Bull 132, 111008 (2020).
Oh, J. et al. A trade-off-free fluorosulfate-based flame-retardant electrolyte additive for high-energy lithium batteries. J. Mater. Chem. A. 10, 21933–21940 (2022).
Zhang, M. et al. Effect of micron sized particle on the electrochemical properties of nickel-rich LiNi0.8Co0.1Mn0.1O2 cathode materials. Ceram. Int 46, 4643–4651 (2020).
Liu, S., Xiong, L. & He, C. Long cycle life lithium ion battery with lithium nickel cobalt manganese oxide (NCM) cathode. J. Power Sources 261, 285–291 (2014).
Liu, J.-M. et al. Cough event classification by pretrained deep neural network. BMC Med. Inf. Decis. Mak. 15(Suppl 4), S2 (2015).
Hacıefendioğlu, K., Demir, G. & Başağa, H. B. Landslide detection using visualization techniques for deep convolutional neural network models. Nat. Hazards 109, 329–350 (2021).
Qayyum, A., Meriaudeau, F. & Chan, G. C. Y. Classification of atrial fibrillation with pre-trained convolutional neural network models. In Proc. 2018 IEEE-EMBS Conference on Biomedical Engineering and Sciences (IECBES) 594–599 (IEEE, Sarawak, Malaysia, 2018).
Deng, J. et al. ImageNet: A large-scale hierarchical image database. In Proc. 2009 IEEE Conference on Computer Vision and Pattern Recognition 248–255 (IEEE, Miami, FL, USA 2009).
Li, L. et al. Recent progress on electrolyte functional additives for protection of nickel-rich layered oxide cathode materials. J. Energy Chem. 65, 280–292 (2022).
Han, G., Li, B., Ye, Z., Cao, C. & Guan, S. The cooperative effect of vinylene carbonate and 1,3-propane sultone on the elevated temperature performance of lithium-ion batteries. Int. J. Electrochem. Sci. 7, 12963–12973 (2012).
Zhang, B. et al. Role of 1,3-propane sultone and vinylene carbonate in solid electrolyte interface formation and gas generation. J. Phys. Chem. C. 119, 11337–11348 (2015).
Xia, J. et al. Comparative study on methylene methyl disulfonate (MMDS) and 1,3-propane sultone (PS) as electrolyte additives for Li-ion batteries. J. Electrochem. Soc. 161, A547–A553 (2014).
Xu, D. et al. Exploring synergetic effects of vinylene carbonate and 1,3-propane sultone on LiNi0.6Mn0.2Co0.2O2/graphite cells with excellent high-temperature performance. J. Power Sources 437, 226929 (2019).
Xia, J. et al. Comparative study on prop-1-ene-1,3-sultone and vinylene carbonate as electrolyte additives for Li(Ni1/3Mn13Co1/3)O2/graphite pouch cells. J. Electrochem. Soc. 161, A1634–A1641 (2014).
Aurbach, D. et al. On the use of vinylene carbonate (VC) as an additive to electrolyte solutions for Li-ion batteries. Electrochim. Acta 47, 1423–1439 (2002).
Ota, H., Sakata, Y., Inoue, A. & Yamaguchi, S. Analysis of vinylene carbonate derived SEI layers on graphite anode. J. Electrochem. Soc. 151, A1659 (2004).
Acknowledgements
This work was supported the KAIST-funded Global Singularity Research Program for 2022 and 2023 under award number 1711100689 and the National Research Foundation (NRF) grant funded by the Korea government (MSIT) (2020M3H4A3081880, RS-2023-00247245). J.C.A. acknowledges support from the DOE Data Reduction for Science award Real-Time Data Reduction Codesign at the Extreme Edge for Science, the Army/ARL via the Collaborative for Hierarchical Agile and Responsive Materials (CHARM) under cooperative agreement W911NF-19-2-0119, and National Science Foundation under grant OAC:DMR:CSSI–2246463.
Author information
Authors and Affiliations
Contributions
J.O., J.Y., C.H.L., and S.H. conceived and designed the experiment. J.O. and K.M.K. prepared the NCM samples and obtained the SEM images. J.Y., C.H.L., B.M., and J.C.A. designed the machine learning model and optimized the model. J.O., J.Y., B.M., and S.H. wrote the manuscript and all the authors discussed and commented on the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Oh, J., Yeom, J., Madika, B. et al. Composition and state prediction of lithium-ion cathode via convolutional neural network trained on scanning electron microscopy images. npj Comput Mater 10, 88 (2024). https://doi.org/10.1038/s41524-024-01279-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41524-024-01279-6
